6 Key Insights
Deep dives into the diamond dataset revealing pricing patterns, shape relationships, and the premium value of fancy color diamonds.
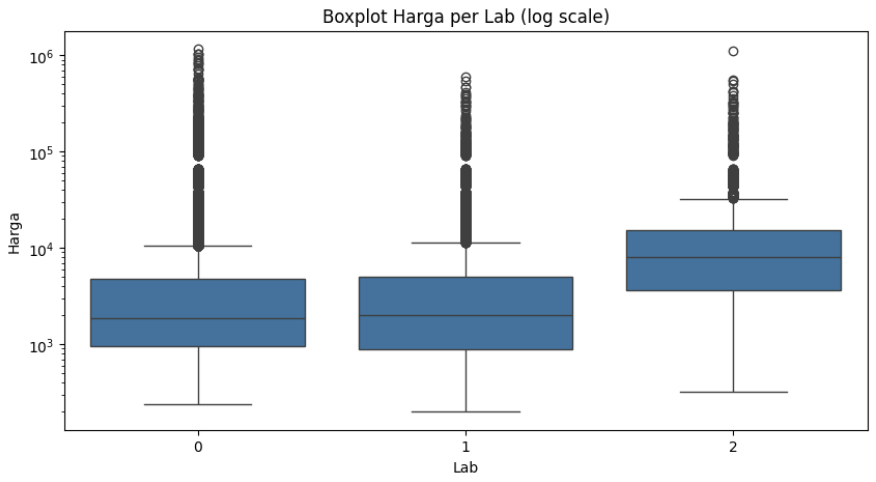
Lab vs Price Distribution
Distribution across labs is imbalanced — Lab 0 dominates in volume. Labs 0 and 1 show overlapping price ranges on log scale, while Lab 2 tends to certify higher-value diamonds, with a higher median and upper quartile.
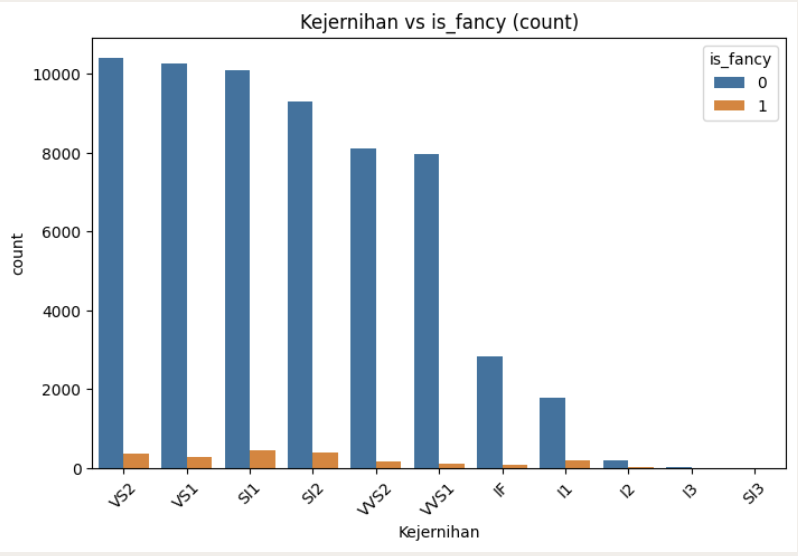
Clarity: Fancy vs Non-Fancy
Both fancy and standard diamonds concentrate at VS2, VS1, SI1, SI2 clarity grades. No significant clarity shift exists between groups.
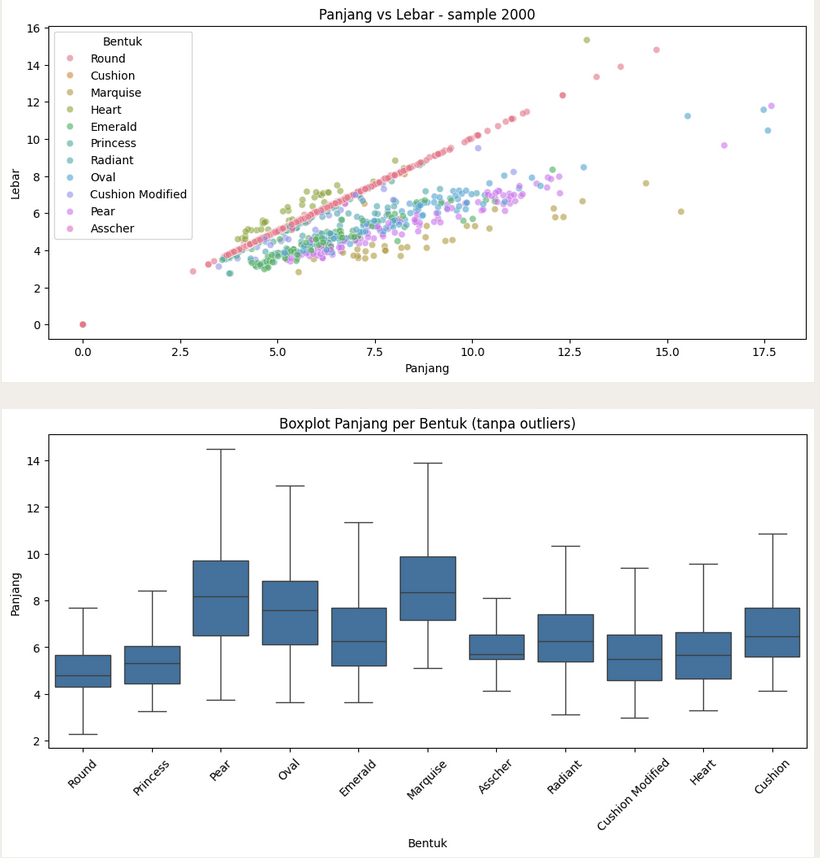
Shape & Dimension Distribution
Round cuts show the most symmetric length/width ratio. Elongated cuts (Marquise, Pear, Oval) have much larger length vs width. Princess & Asscher approach square proportions.
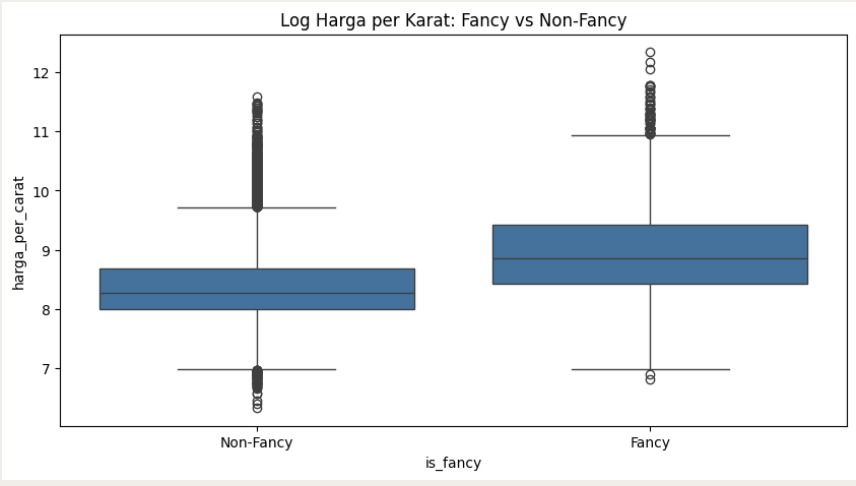
Fancy Color Premium
Fancy color diamonds command a price-per-carat that is over 2× higher on average compared to standard diamonds. The entire distribution shifts upward — not just outliers.
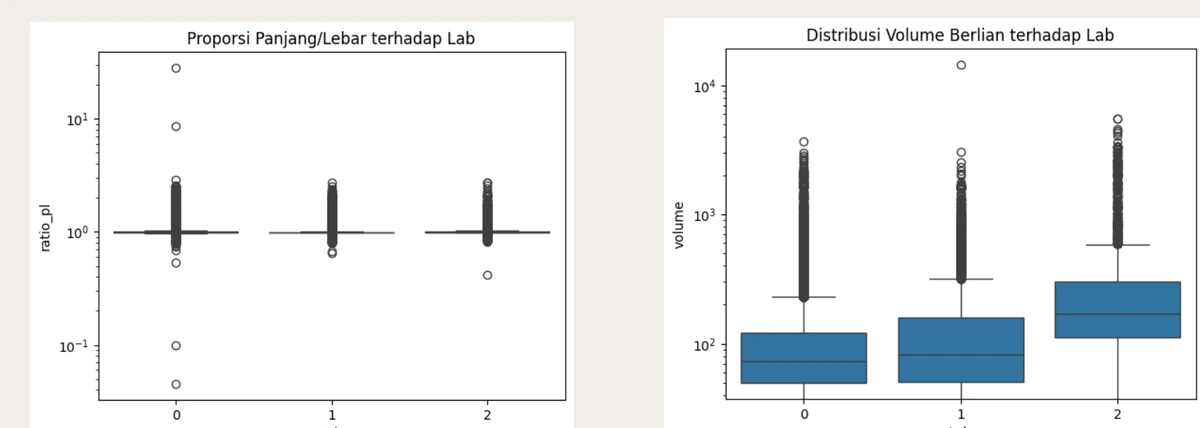
Dimension Ratios Across Labs
Length/width ratio is consistent across all three labs (majority near 1:1). However, volume differs notably — Lab 2 handles larger diamonds on average.
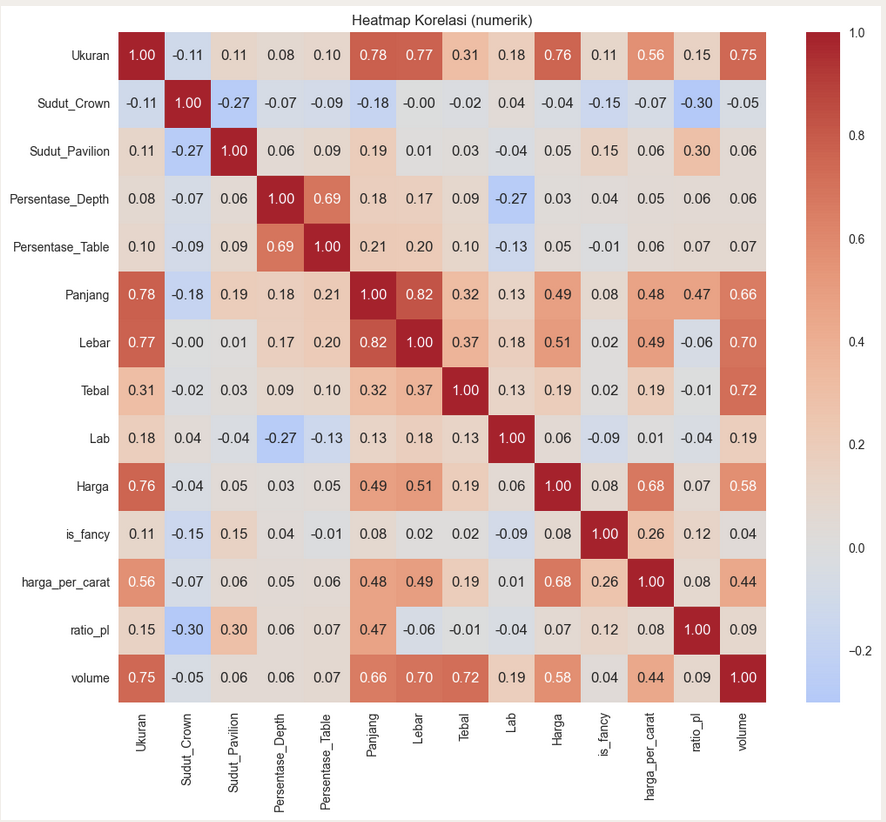
Correlation Heatmap — Numeric Features
Carat (Ukuran) shows the strongest correlation with price at r = 0.76. Price-per-carat follows at r = 0.68. Physical dimensions (width 0.51, length 0.49) also contribute significantly.